自宅や職場のPCに外からアクセスしたいけれど、「ルーターのポート開放は難しそう」「マンションの共有回線で設定を変更できない」といった理由で、諦めてしまっていませんか?
今回は、Windows 11 Pro 端末に SoftEther VPN Server をインストールし、公式の無料中継サービスである「VPN Azure」 を利用して、ポート開放不要でリモートデスクトップ接続を実現する方法 を解説します。
本記事は前編・後編の2部構成です。前編 :接続先となる Windows 11 Pro 端末に
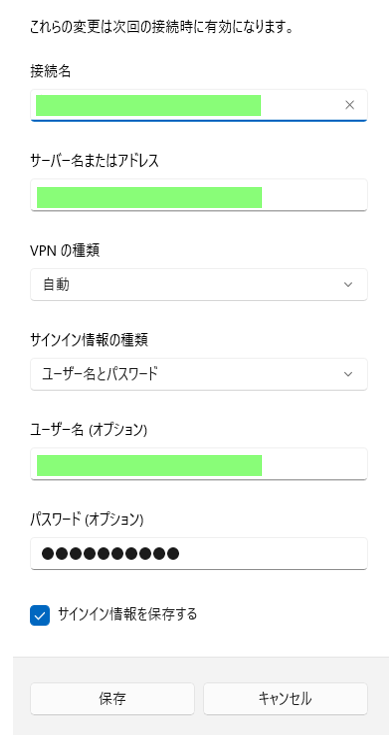
後編 :接続元の Windows 端末に VPN 接続を設定し、
注:記載内容の正確性には十分注意を払っていますが内容や動作を保証するものではありません。
前提環境(今回の構成)
今回は以下の環境を使用しました。
OS: Windows 11 Pro :
ソフト: SoftEther VPN Server
ネットワーク環境 :
1.サーバー側(接続先PC)の設定
まずは、接続先となる Windows 11 Pro PC での作業です。
SoftEther VPN Server のダウンロード
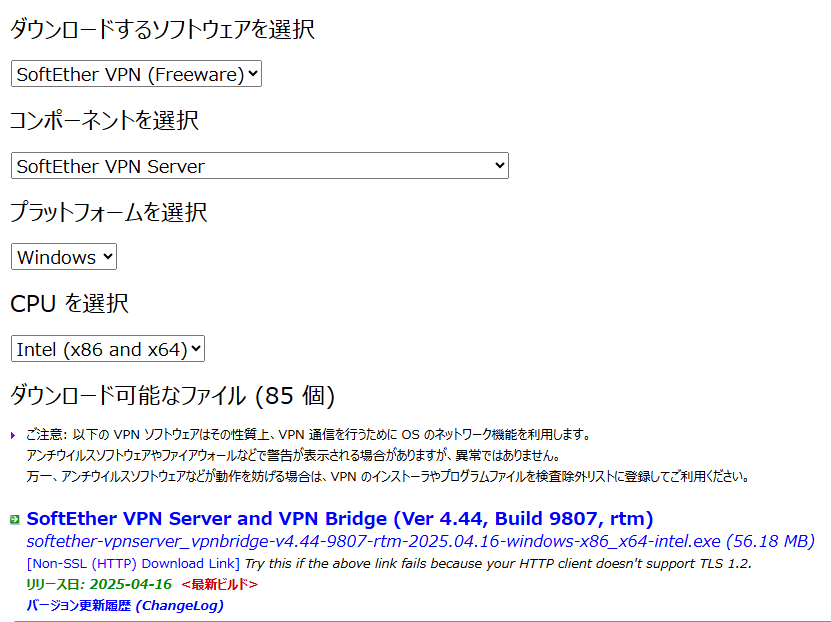
SoftEther ダウンロード センター からSoftEther VPN Server を以下の手順でダウンロードします。
ダウンロードするソフトウェアを選択 : SoftEther VPN(Freeware)
コンポーネントを選択: SoftEther VPN Server
プラットフォームを選択:Windows
最新のインストーラーが先頭に表示されます。
SoftEther VPN Server のインストール
ダウンロードしたインストーラーを起動します。
「次へ」
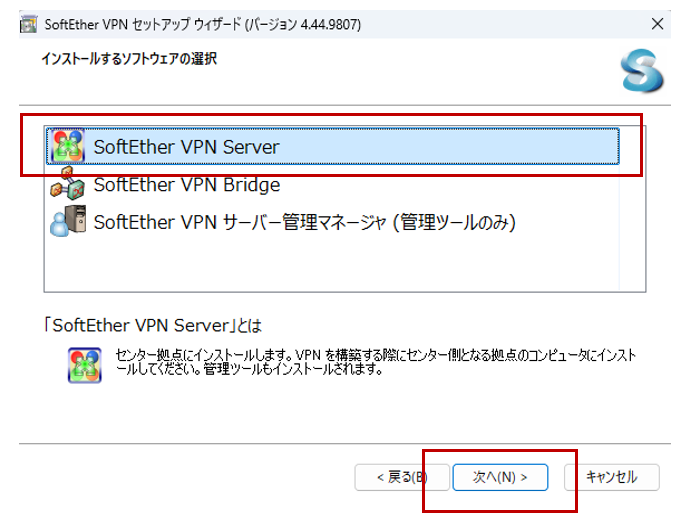
「SoftEther VPN Server」を選択して「次へ」
使用許諾契約書や重要事項説明書の項は「次へ」
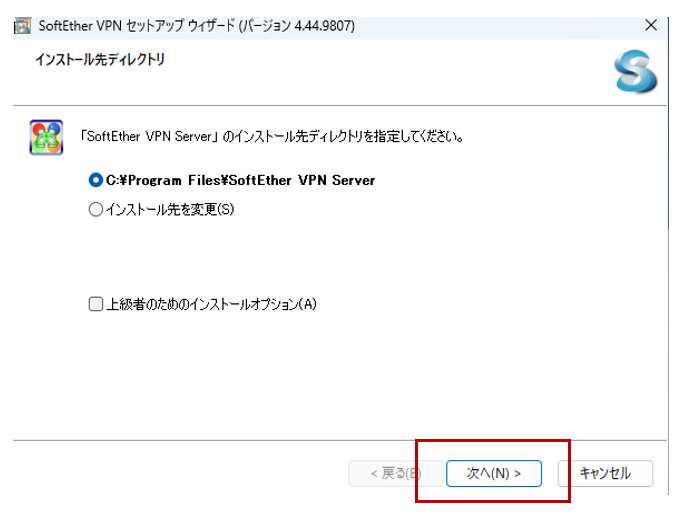
インストール先を指定して「次へ」
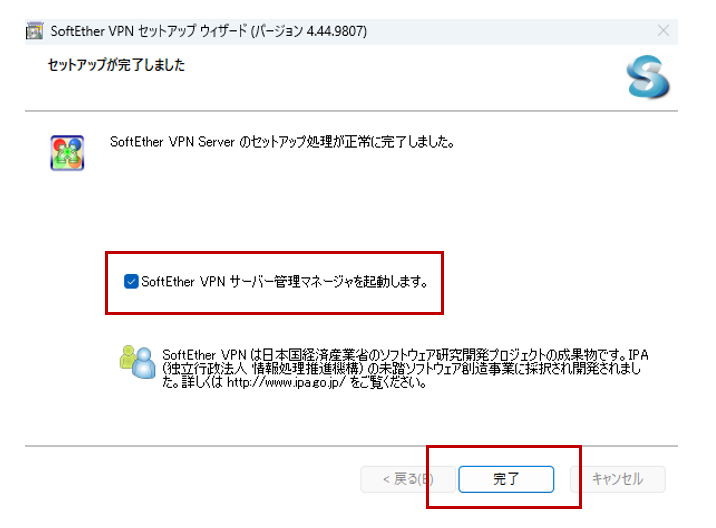
管理マネージャー起動にチェックを入れて「完了」
SoftEther VPN Server の設定
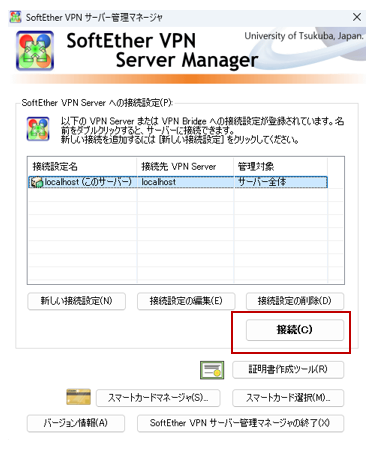
管理マネージャー画面が表示されます
接続
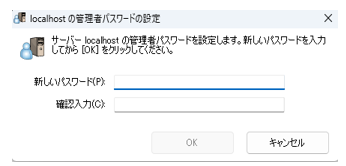
管理者パスワードを設定します。設定したパスワードは忘れないようメモしてください。
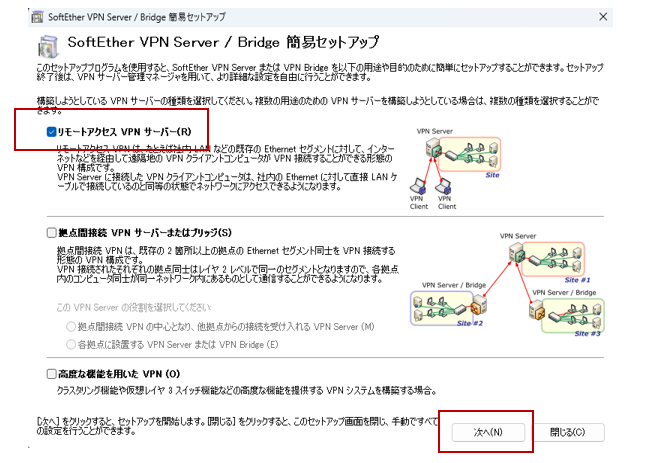
「リモートアクセスサーバー」にチェックを入れて「次へ」
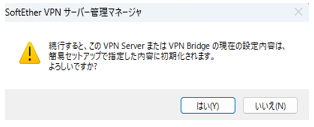
「はい」
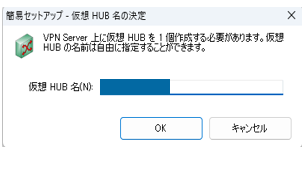
仮想HUB名に任意の名称を入力して「OK」
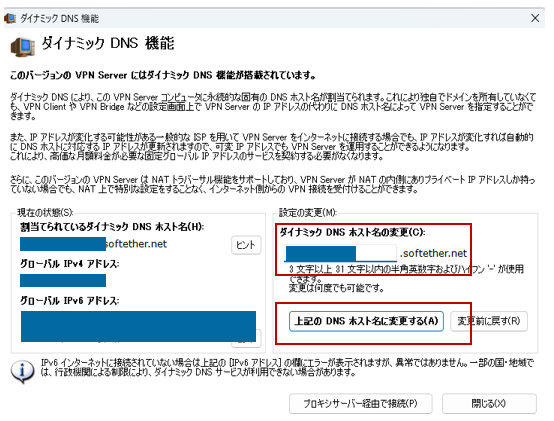
ダイナミックDNSホスト名はユニークな名称にする
L2TP/IPsec の設定画面が表示されるが今回はこのプロトコルは使用しないので「キャンセル」をクリックする。
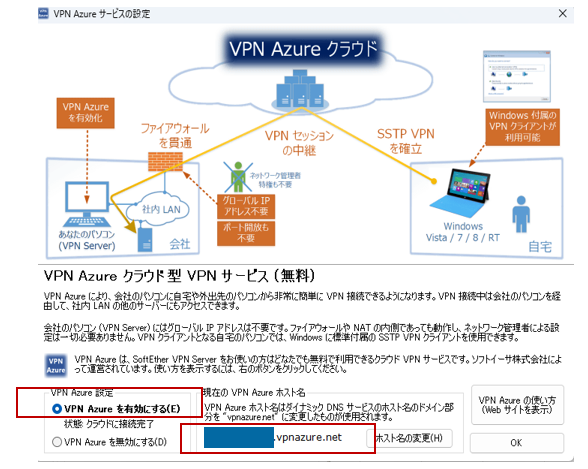
「VPN Azureを有効にする」を選択します。VPN Azure ホスト名をメモに控えておいてください(リモート設定の際に使用します)。「OK」をクリック。
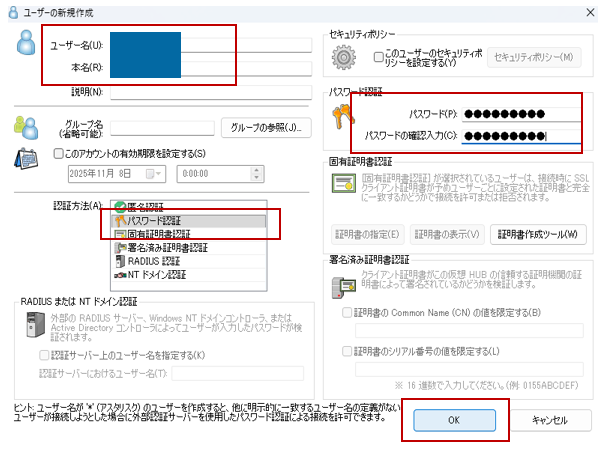
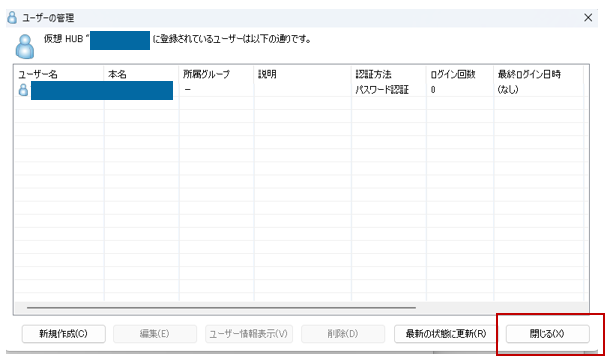
「ユーザーを作成する」をクリック。
「ユーザー名」を入力して「パスワード認証」を選択。パスワードを設定して「OK」をクリック。※クライアント端末からの接続設定で使うのでユーザー名とパスワードはメモに控えておいてください。
「閉じる」をクリック。
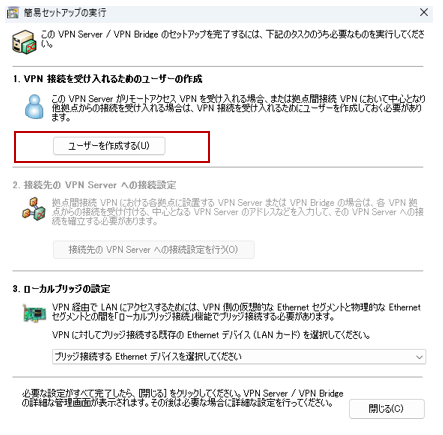
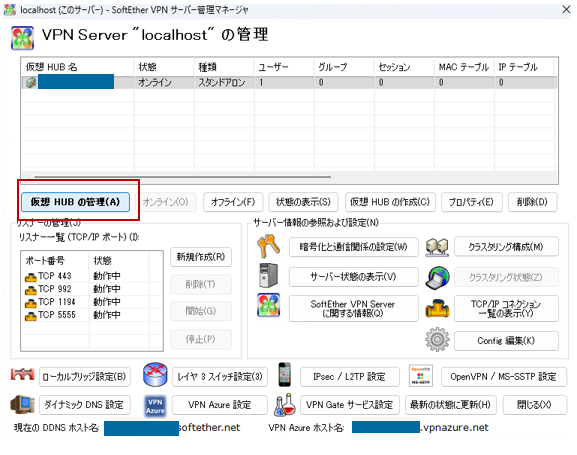
「仮想HUBの管理」をクリック。
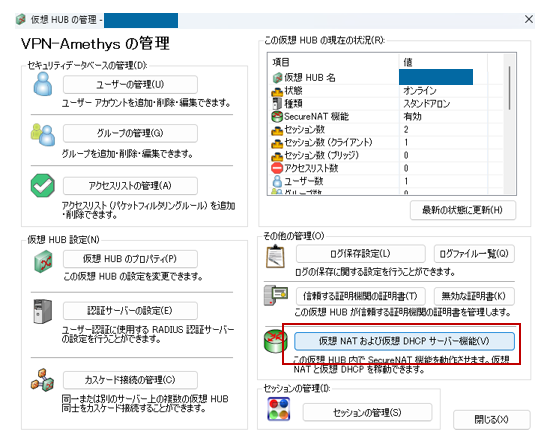
「仮想NATおよび仮想DHCPサーバ機能」をクリック。
「SecureNAT機能を有効にする」をクリック。
確認作業
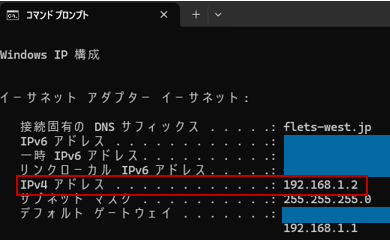
コマンドプロンプトを開いて「ipconfig」コマンドを実行してIPv4アドレスをメモしておきます。(クライアント端末のリモートデスクトップ接続設定時に使用します。)
まとめ
今回は接続先となるWindows11 Pro端末にSoftEther VPN Server をインストールし、設定を施す手順まで解説しました。