
ローカルLLMを手軽に試せる「LM Studio」。しかし、設定画面を開くと「GPUオフロード」「KVキャッシュ」「Flash Attention」といった聞き慣れない用語が並び、戸惑う方も多いのではないでしょうか。
この記事では、LM Studioの設定項目に絞って、各用語の意味と、快適に動かすための最適化のポイントを分かりやすく解説します。
注:記載内容の正確性には十分注意を払っていますが内容や動作を保証するものではありません。
ローカルLLMを使う上での基本用語
LM Studioでモデルを選ぶ際によく目にする基本用語です。
| 用語 | 説明 |
|---|---|
| GGUF | LM Studioで最も一般的に使われるファイル形式です。CPUとGPUの両方で効率よく動作するように設計されています。 |
| 量子化 (Quantization) | モデルのサイズを軽量化する技術です。「4-bit (Q4_K_M)」などの表記があり、ビット数が小さいほどメモリ消費が少なくなりますが、わずかに賢さが低下します。 |
| VRAM | グラフィックボード(GPU)のメモリです。ローカルLLMの速度は、このVRAMにどれだけモデルを詰め込めるかが大きく影響します。 |
1.モデルを動かす「エンジン」を選ぼう(My Engine編)
LM Studioでは、同じモデルでも どの計算エンジンを使うか によって速度・安定性・対応環境が大きく変わります。これは「車のエンジンを選ぶ」のと同じで、PCのパーツ(GPUやCPU)に合わせて最適なものを選ぶ必要があります。合わないEnginを選ぶとモデルのロード時にエラーになります。
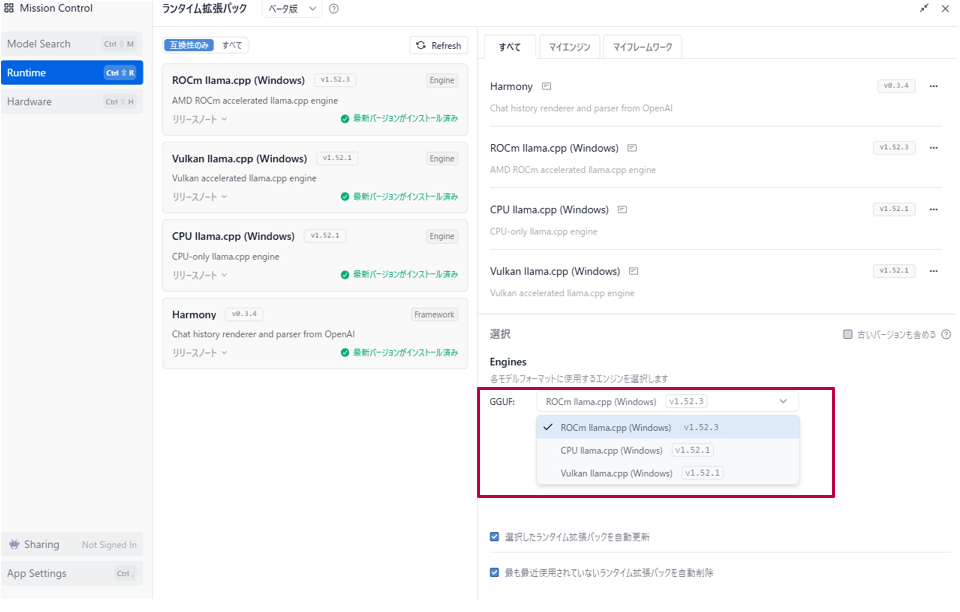
- CUDA llama.cpp: NVIDIA製グラフィックボード(RTXシリーズなど)を使っているならこれを使用しましょう。最も高速です。
- Vulkan llama.cpp: AMD(Radeon)やIntelのGPUを使っている場合に有効な、汎用的な加速エンジンです。
- ROCm llama.cpp: AMD(Radeon)ユーザーは第一選択。大容量VRAMで安定動作。
- CPU llama.cpp: グラボを使わず、PCのメイン頭脳(CPU)だけで計算します。速度は遅いですが、最も安定しています。
2.ロード設定:速度とメモリの設定(Load編)
モデルを読み込む際の設定です。最もパフォーマンスに影響するところですがここでは特に重要な項目について説明しています。
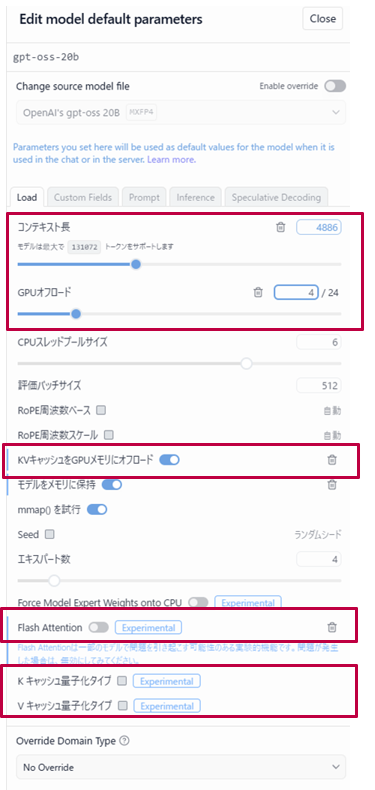
| load設定項目 | 説明 |
|---|---|
| コンテキスト長 | モデルが一度に覚えられるトークン数の上限。値を大きくすると長文対応が可能になるが、その分VRAM消費も増える。通常会話なら4,096〜8,192程度、長文生成なら32,768以上も設定できるが、環境に応じて調整が必要。 |
| GPUオフロード | モデルの層をどれだけ GPU に割り当てるかを決める設定。VRAM容量が多ければ全層をGPUに載せて高速化できるが、容量不足だとエラーやクラッシュの原因になる。少しずつ層数を調整しながら最適値を探すのが基本。 |
| 量子化KVキャッシュをGPUメモリにオフロード | 会話の履歴(キャッシュ)を高速なGPUメモリに置く設定。オンにするとレスポンスが滑らかになり、長文や複数ターンの会話でも速度低下が少ない。ただしVRAM消費が増えるため、容量が少ない環境では注意が必要。 |
| K/Vキャッシュ量子化タイプ | キャッシュデータを圧縮してVRAM消費を抑える機能。VRAMが少ない環境でも長文会話を可能にする設定。精度は多少落ちるが、安定して長文を扱いたい場合に有効。 |
| Flash Attention(実験的機能) | 最新の計算最適化技術で、GPU上での処理効率を大幅に改善する。対応GPU(RTX 30/40シリーズなど)ならオンにすることで速度が劇的に向上する。非対応GPUでは使えないか不安定になる場合がある。 |
3.推論設定:回答の「性格」を変える(Inference編)
モデルが文字を出力する際の調整項目です。回答が「つまらない」「支離滅裂」と感じたらここを見直します。
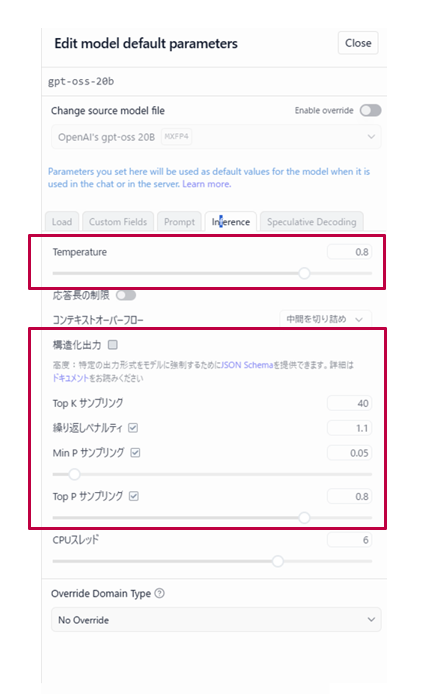
| Inference設定項目 | 説明 |
|---|---|
| Temperature | 回答の「創造性」です。値を上げると個性的で予測不能に、下げると堅実で正確な回答になります。 |
| Top K / Top P / Min P サンプリング | 次に来る言葉の候補をどう絞り込むかの設定です。これらを組み合わせることで、自然な日本語のつながりを作ります。 |
| 繰り返しペナルティ | 同じ言葉を何度も繰り返してしまう「ループ現象」を防ぎます。目安:1.1〜1.2程度が自然で低すぎると「同じ言葉の連発」になりやすく高すぎると「必要な繰り返し」(例:詩や強調表現)が不自然に削られます。 |
| 構造化出力 (JSON Schema) | 開発者向けの設定です。AIの回答を特定のプログラム形式(JSON)に強制できます。 |
| コンテキストオーバーフロー | 記憶容量(コンテキスト長)を超えた際、古い会話をどう捨てるかを選べます(「中間を切り詰め」など)。 |
まとめ
今回の記事ではllmモデルとして gpt-oss-20b の設定項目をベースに解説いたしました。ご自身の環境に合わせて以下のチェックリストを実施して頂ければ幸いです。
自分のPCに合わせた最適化「チェックリスト」
- 自分のGPUに合ったエンジンを選ぶ
- GPUオフロードを最大まで試す
- Flash Attentionをオンにする
- Temperatureを0.7~0.8に調整する
- 長文ならKVキャッシュ量子化を活用